MERLIon CCS Challenge: A English-Mandarin code-switching child-directed speech corpus for language identification and diarization
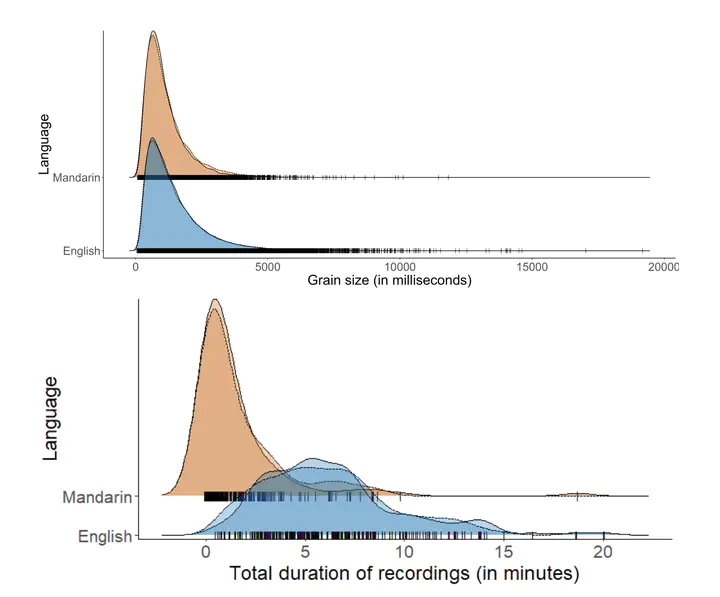
To enhance the reliability and robustness of language identification (LID) and language diarization (LD) systems for heterogeneous populations and scenarios, there is a need for speech processing models to be trained on datasets that feature diverse language registers and speech patterns. We present the MERLIon CCS challenge, featuring a first-of-its-kind Zoom video call dataset of parent-child shared book reading, of over 30 hours with over 300 recordings, annotated by multilingual transcribers using a high-fidelity linguistic transcription protocol.
Xiangyu Zhang
My research interests include Speech and Language Technology, Multimodal, Digital Health